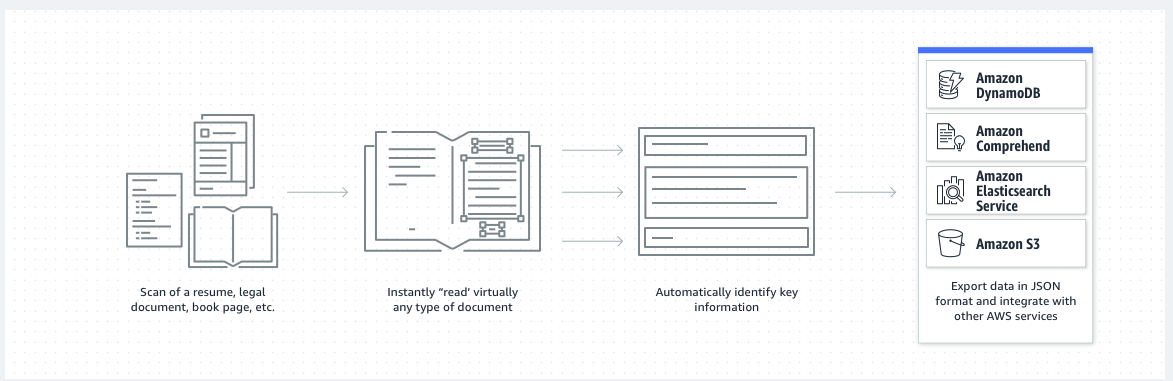
At Mobilise Cloud, we’re always trying to help our customers leverage cloud services to improve their digital services and drive value into their business processes. Sometimes, this requires us to demonstrate the art of the possible to get our customers thinking about where they could utilise cloud services and tooling within their business. Often this is through the use of proof of concepts which aim to inspire engineers and business users to develop ideas and business cases to optimise and automate existing processes, and innovate new processes using iterative prototyping.
A service which has a lot of potential to optimise and automate business workflows across industries is Amazon Textract – a document analysis service that uses machine learning to accurately extract information from documents. Where this differs from traditional OCR (Optical Character Recognition) is Textract’s ability to automatically detect items such as tables, structured data and handwriting with no input from the user. Common use cases include
- Importing documents and forms into business applications,
- Creating smart search indexes and
- Building automated document processing workflows.
Let’s take a look at it in action…
Legal documents that have been scanned are notoriously difficult to search and even if you can find a way of searching for text, extracting formatted text is very difficult and extracting data from tables can be extremely frustrating.
If you’ve ever looked through company information held on Companies House, you may have noticed all of the filing information including accounts and articles of association are pretty poor quality scanned documents. So as a challenge we are going to use Textract to automate the extraction of Profit and Loss information from a set of accounts.
 Looking at this PDF, you can see that the focus is a little out making the text hard to read as well as blotches or imperfections picked up through the scanning process. Now because this information is stored in an image/PDF file it makes it hard to aggregate, index and search the information – especially when you scale this out to thousands of businesses.
Looking at this PDF, you can see that the focus is a little out making the text hard to read as well as blotches or imperfections picked up through the scanning process. Now because this information is stored in an image/PDF file it makes it hard to aggregate, index and search the information – especially when you scale this out to thousands of businesses.
What happens if we run this document through Amazon Textract?
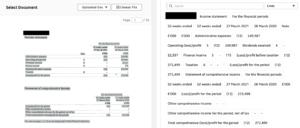 On the left hand side we can see Amazon Textract scanning the PDF file and identifying all of the text to extract. On the right hand side you can see the RAW output from Textract which has accurately extracted all text within the document. Furthermore, all of this extracted text is now searchable and returns results in rapid time whilst also using bounding boxes to identify the source content (source on left, extracted text on right) for moderation.
On the left hand side we can see Amazon Textract scanning the PDF file and identifying all of the text to extract. On the right hand side you can see the RAW output from Textract which has accurately extracted all text within the document. Furthermore, all of this extracted text is now searchable and returns results in rapid time whilst also using bounding boxes to identify the source content (source on left, extracted text on right) for moderation.
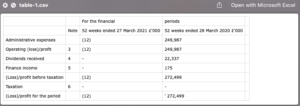
Now this in itself isn’t very useful because there would now be quite a bit of work to put some structure around the extracted text and subsequently ensure that any future scanned document follow the same pattern so they don’t break the model. However, as mentioned Amazon Textract can identify tables and individual cells within tables.
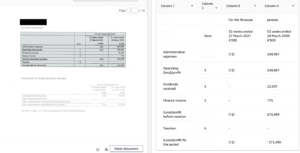 Here, Textract has first identified that a tables is displayed on this page, secondly identified the columns and lastly populated the values in the correct row. This is all done automatically out of the box with no further configuration and can work for any type or size of table meaning you aren’t tied to particular solutions or implementations which expect for example the 4th column to be the totals column on every single import of a table. Clicking on table 2 automatically displays the next table in the document and the extracted cells.
Here, Textract has first identified that a tables is displayed on this page, secondly identified the columns and lastly populated the values in the correct row. This is all done automatically out of the box with no further configuration and can work for any type or size of table meaning you aren’t tied to particular solutions or implementations which expect for example the 4th column to be the totals column on every single import of a table. Clicking on table 2 automatically displays the next table in the document and the extracted cells.
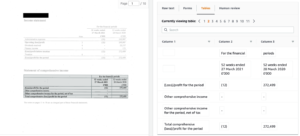 You can also export this information to CSVs…
You can also export this information to CSVs…
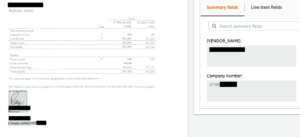
 Additionally, you can analyse the document from an expenses perspective which automatically pull the Vendors name and company number from the document.
Additionally, you can analyse the document from an expenses perspective which automatically pull the Vendors name and company number from the document.
 The screenshots above are from Amazon’s Textract Demonstration section which provide the user with a simple UI to display the features and capabilities of Textract.
The screenshots above are from Amazon’s Textract Demonstration section which provide the user with a simple UI to display the features and capabilities of Textract.
The real power comes from using the underlying APIs to automate the reading, extraction, storage, indexing, searching and integration of data with your businesses applications.
In this example imagine being able to automatically ingest thousands of records like the ones above, automatically pull all the information from them, collate it into tables and then ingest it into a datawarehouse for analytical processing. You can even build in human review workflows – each time data is ingested, Textract provides a confidence level for how accurately it believes it has read a value. If this value is too low, we can kick off a workflow to have a human review the data before committing it to the datawarehouse.


